Abstract
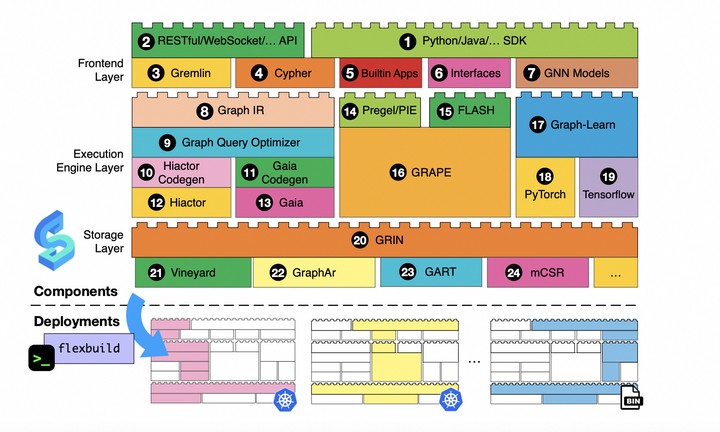
Graph computing has become increasingly crucial in processing large-scale graph data, with numerous systems developed for this purpose. Two years ago, we introduced GraphScope as a system addressing a wide array of graph computing needs, including graph traversal, analytics, and learning in one system. Since its inception, GraphScope has achieved significant technological advancements and gained widespread adoption across various industries. However, one key lesson from this journey has been understanding the limitations of a “one-size-fits-all” approach, especially when dealing with the diversity of programming interfaces, applications, and data storage formats in graph computing. In response to these challenges, we present GraphScope Flex, the next iteration of Graph- Scope. GraphScope Flex is designed to be both resource-efficient and cost-effective, while also providing flexibility and user-friendliness through its LEGO-like modularity. This paper explores the architectural innovations and fundamental design principles of GraphScope Flex, all of which are direct outcomes of the lessons learned during our ongoing development process. We validate the adaptability and efficiency of GraphScope Flex with extensive evaluations on syn- thetic and real-world datasets. The results show that GraphScope Flex achieves 2.4$\times$ throughput and up to 55.7$\times$ speedup over other systems on the LDBC Social Network and Graphalytics benchmarks, respectively. Furthermore, GraphScope Flex accomplishes up to a 2,400$\times$ performance gain in real-world applications, demonstrating its proficiency across a wide range of graph computing scenarios with increased effectiveness.