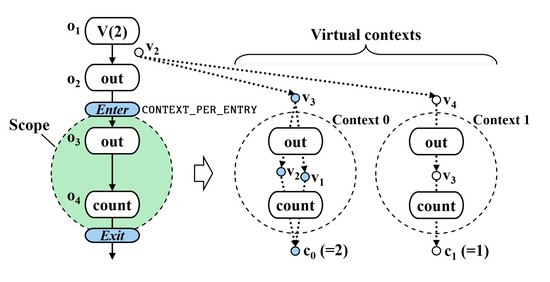
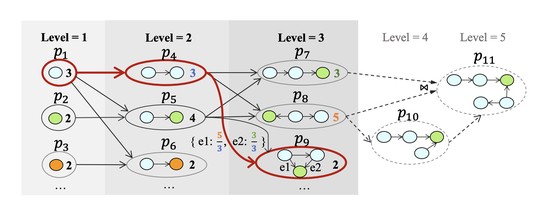
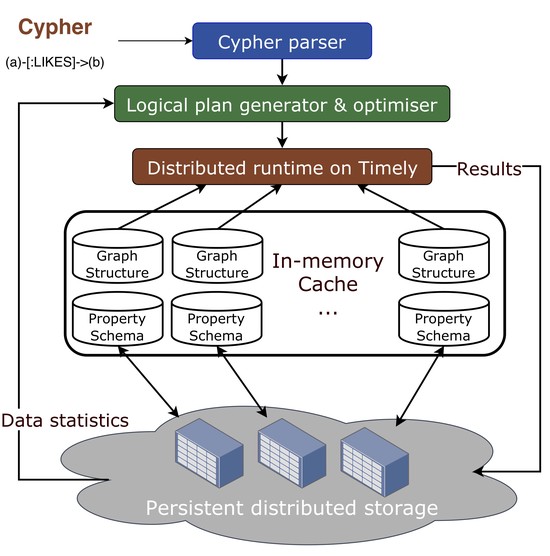
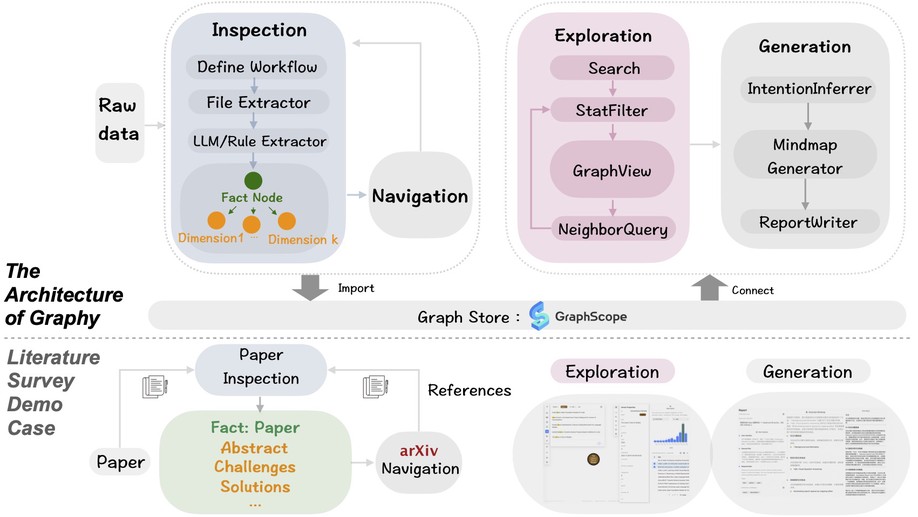
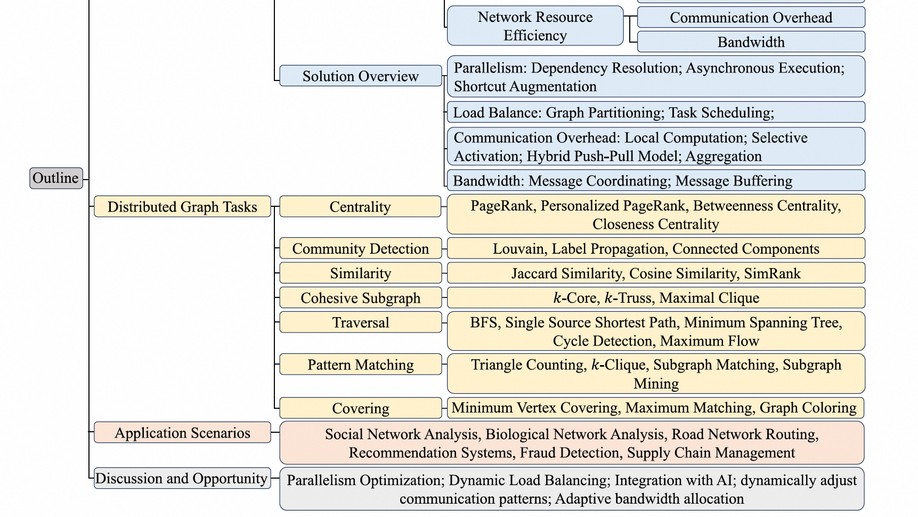
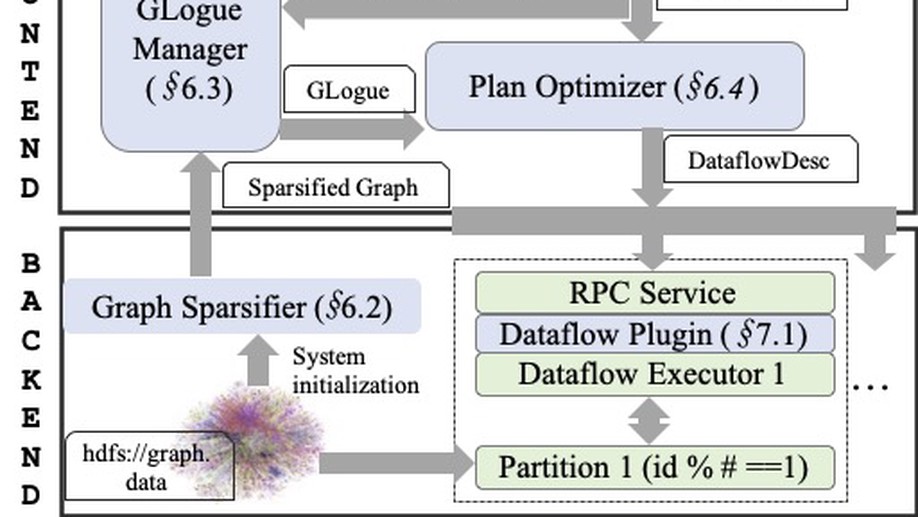
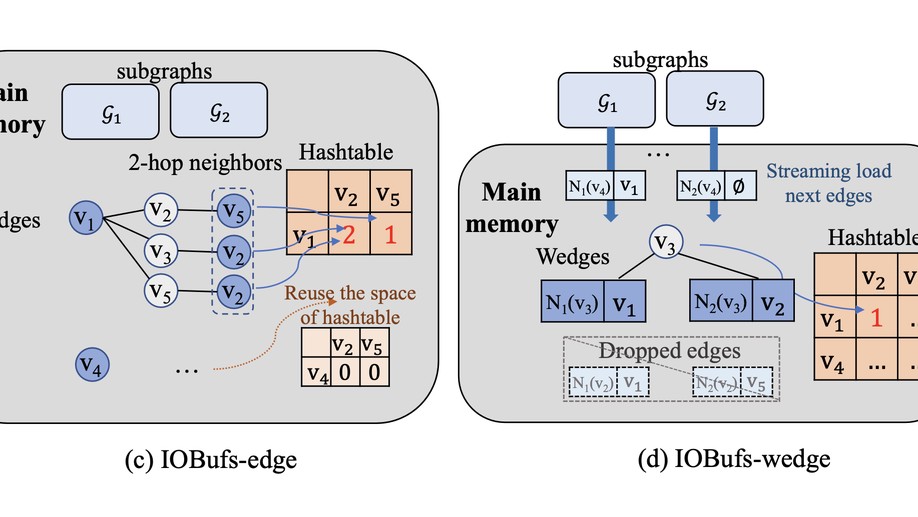
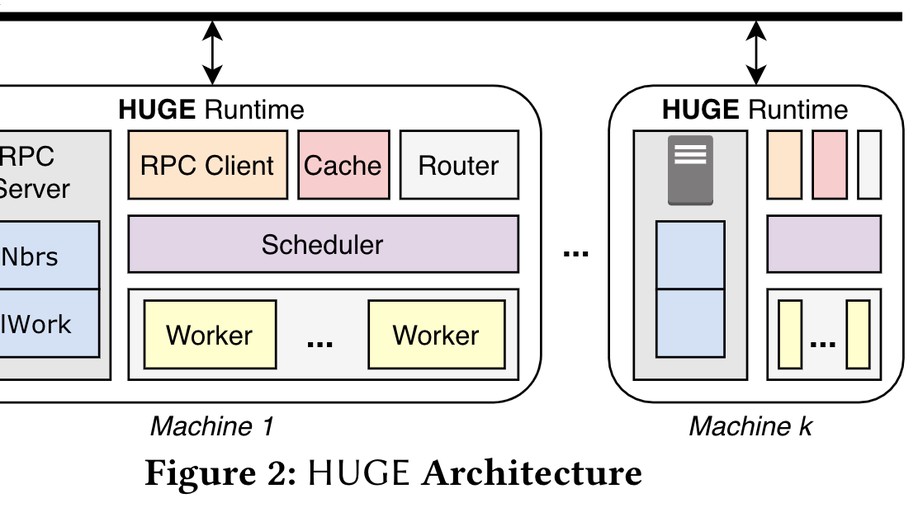
Biography
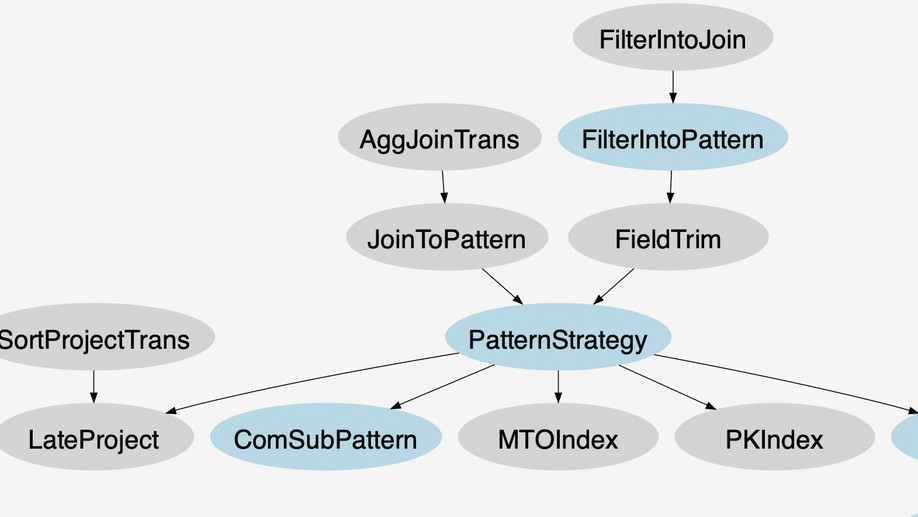
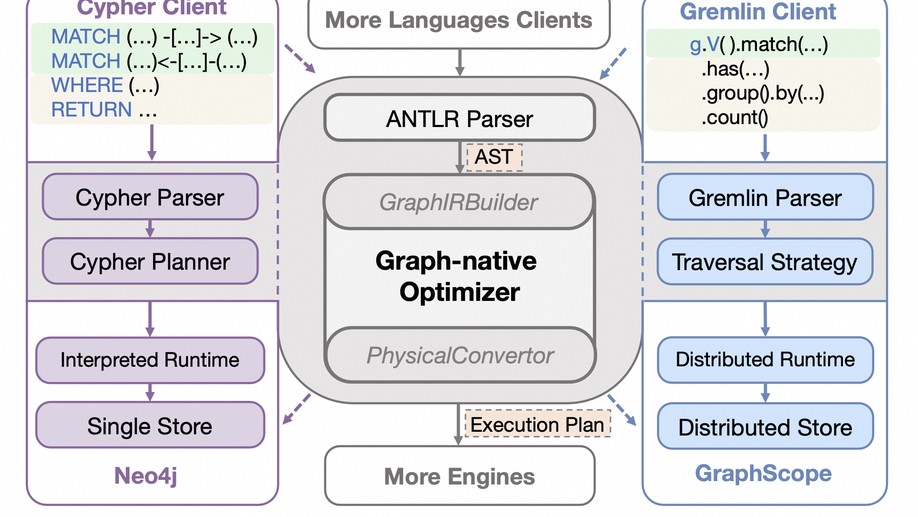
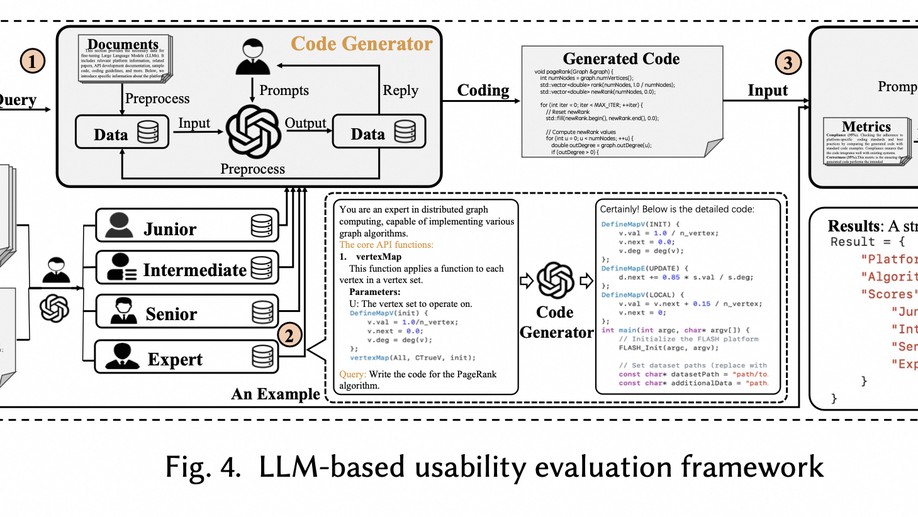
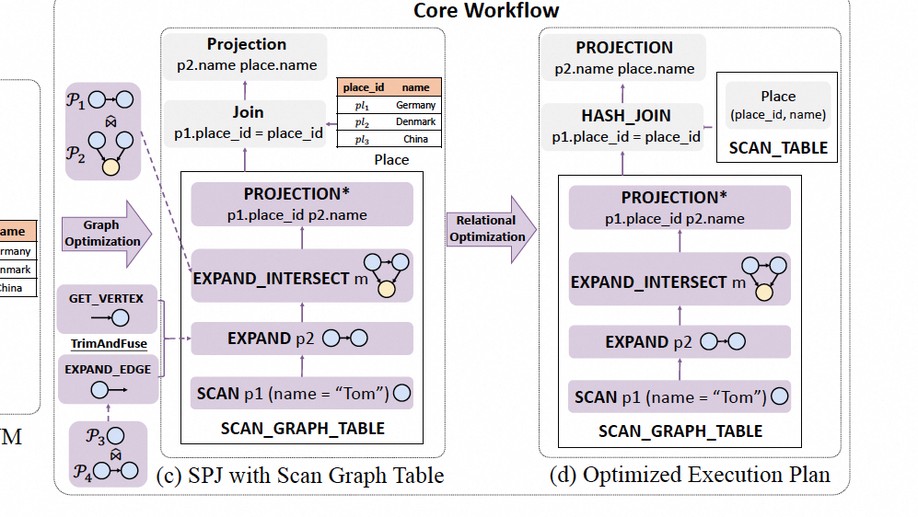
Dr. Longbin Lai obtained his Bachelor’s and Master’s degrees from Shanghai Jiao Tong University (SJTU) in 2010 and 2013, respectively. He then pursued his Ph.D. studies in the Database Group at the School of Computer Science and Engineering (CSE), University of New South Wales (UNSW), Sydney, under the supervision of Prof. Xuemin Lin and Prof. Lu Qin. He completed his Ph.D. in March 2017, and his thesis is available here. Dr. Lai joined Alibaba to develop large-scale graph data analytics systems for its e-commerce platform. He is also a lead contributor to the open-source project GraphScope. His work includes GAIA, a distributed dataflow system for large-scale graph queries; GLogS, a distributed interactive pattern matching system; and GOpt, a unified graph query optimization framework. Currently, he is a member of Alibaba Tongyi Lab, where he leads research and development initiatives focusing on innovative applications of Large Language Models (LLMs).
Interests
- Big Data Management
- Graph Database
- Distributed Processing
- Query Optimizations
- Large Language Models
Education
PhD in Computer Science and Engineering, 2017
University of New South Wales, Sydney
Master in Computer Engineering, 2013
Shanghai Jiao Tong University
BSc in Information Security, 2010
Shanghai Jiao Tong University